Autors:
Evelina Leivada, Fritz Günther & Vittoria DentellaTítol:
Reply to Hu et al: Applying different evaluation standards to humans vs. Large Language Models overestimates AI performanceEditorial: PNAS 121(36), e2406752121 (National Academy of Sciences)
Data de publicació: 26 d'agost, 2024
Text complet
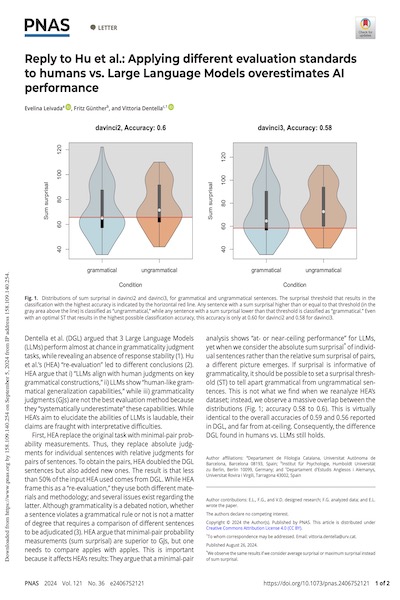
Dentella et al. (DGL) argued that 3 Large Language Models (LLMs) perform almost at chance in grammaticality judgment tasks, while revealing an absence of response stability (1). Hu et al.’s (HEA) “re-evaluation” led to different conclusions (2). HEA argue that i) “LLMs align with human judgments on key grammatical constructions,” ii) LLMs show “human-like grammatical generalization capabilities,” while iii) grammaticality judgments (GJs) are not the best evaluation method because they “systematically underestimate” these capabilities. While HEA’s aim to elucidate the abilities of LLMs is laudable, their claims are fraught with interpretative difficulties.









