6 febrer, 2024

Autors:
Vittoria Dentella, Camilla Masullo & Evelina Leivada
Títol:
Bilingual disadvantages are systematically compensated by bilingual advantages across tasks and populationsEditorial: Scientific Reports (Springer Nature)
Data de publicació: 24 de gener del 2024
Text completBilingualism is linked to both enhanced and hampered performance in various cognitive measures, yet the extent to which these bilingual advantages and disadvantages co-occur is unclear. To address this gap, we perform a systematic review and two quantitative analyses. First, we analyze results from 39 studies, obtained through the PRISMA method. Less than 50% of the studies that show up as results for the term “bilingual disadvantage” report exclusively a disadvantage, that shows bilinguals performing worse than monolinguals in a task. A Bayesian analysis reveals robust evidence for bilingual effects, but no evidence for differences in the proportion of advantages and disadvantages, suggesting that when results from different cognitive domains such as executive functions and verbal fluency are analyzed together, bilingual effects amount to a zero-sum game. This finding was replicated by repeating the analysis, using the datasets of two recent meta-analyses. We propose that the equilibrium we observe between positive and negative outcomes may not be accidental. Contrary to widespread belief, advantageous and disadvantageous effects are not stand-alone outcomes in free variation. We reframe them as the connatural components of a dynamic trade-off, whereby enhanced performance in one cognitive measure is offset by an incurred cost in another domain.
19 abril, 2024

Autors:
Evelina Leivada, Vittoria Dentella & Fritz Günther
Títol:
Biolinguistics, vol.18Editorial: PsychOpen
Data de publicació: 19 abril, 2024
Text completWe identify and analyze three caveats that may arise when analyzing the linguistic abilities of Large Language Models. The problem of unlicensed generalizations refers to the danger of interpreting performance in one task as predictive of the models’ overall capabilities, based on the assumption that because a specific task performance is indicative of certain underlying capabilities in humans, the same association holds for models. The human-like paradox refers to the problem of lacking human comparisons, while at the same time attributing human-like abilities to the models. Last, the problem of double standards refers to the use of tasks and methodologies that either cannot be applied to humans or they are evaluated differently in models vs. humans. While we recognize the impressive linguistic abilities of LLMs, we conclude that specific claims about the models’ human-likeness in the grammatical domain are premature.
26 agost, 2024
Autors:
Evelina Leivada, Fritz Günther & Vittoria Dentella
Títol:
Reply to Hu et al: Applying different evaluation standards to humans vs. Large Language Models overestimates AI performanceEditorial: PNAS 121(36), e2406752121 (National Academy of Sciences)
Data de publicació: 26 d'agost, 2024
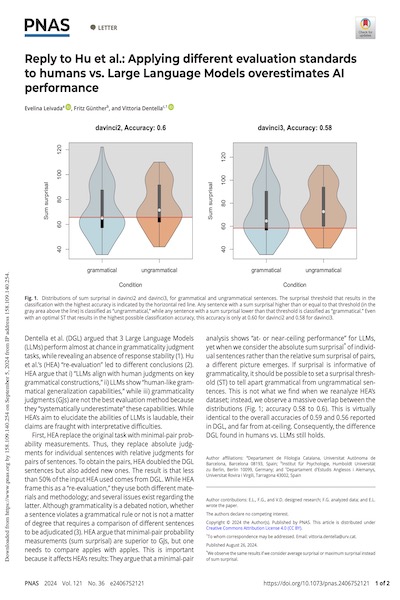
Text completDentella et al. (DGL) argued that 3 Large Language Models (LLMs) perform almost at chance in grammaticality judgment tasks, while revealing an absence of response stability (1). Hu et al.’s (HEA) “re-evaluation” led to different conclusions (2). HEA argue that i) “LLMs align with human judgments on key grammatical constructions,” ii) LLMs show “human-like grammatical generalization capabilities,” while iii) grammaticality judgments (GJs) are not the best evaluation method because they “systematically underestimate” these capabilities. While HEA’s aim to elucidate the abilities of LLMs is laudable, their claims are fraught with interpretative difficulties.
3 setembre, 2024

Autors:
Anna Gavarró & Alejandra Keidel
Títol:
Subject-verb agreement: Three experiments on CatalanEditorial: First Language (Sage Journals)
Data de publicació: Agost, 2024
Pàgines: 22 Text completThis study delves into the syntactic parsing abilities of children and infants exposed to Catalan as their first language. Focusing first on ages 3 to 6, we conducted two sentence-picture matching tasks. In experiment 1, 3 to 4-year-old children failed in identifying singular third-person subjects within null-subject sentences, although they performed above chance in all other scenarios, including plural third-person subjects and sentences with overt full DP subjects. This is reminiscent of the results of Pérez-Leroux for Spanish. In experiment 2, with the same design but involving numeral distractors, children’s performance was above chance level across all conditions from age 3 to 4. Then, in experiment 3, we moved to a younger age range with the help of eye-tracking techniques. The findings revealed that infants at 22 months had the ability to parse subject–verb agreement in sentences with third-person null subjects, and at 19 months there was evidence of parsing for third-person plural null subjects. These findings are inconsistent with the perception of children grappling with syntactic agreement computation. We argue that instances of underperformance in subject–verb agreement parsing identified in the literature often stem from task-related and pragmatic issues rather than core syntactic delay. If so, the putative asymmetry between early production of verbal inflection and late comprehension disappears; rather, the results suggest early establishment of matching operations and mastery of language-specific agreement properties before production starts.




