6 febrer, 2024

Autors:
Vittoria Dentella, Camilla Masullo & Evelina Leivada
Títol:
Bilingual disadvantages are systematically compensated by bilingual advantages across tasks and populationsEditorial: Scientific Reports (Springer Nature)
Data de publicació: 24 de gener del 2024
Text completBilingualism is linked to both enhanced and hampered performance in various cognitive measures, yet the extent to which these bilingual advantages and disadvantages co-occur is unclear. To address this gap, we perform a systematic review and two quantitative analyses. First, we analyze results from 39 studies, obtained through the PRISMA method. Less than 50% of the studies that show up as results for the term “bilingual disadvantage” report exclusively a disadvantage, that shows bilinguals performing worse than monolinguals in a task. A Bayesian analysis reveals robust evidence for bilingual effects, but no evidence for differences in the proportion of advantages and disadvantages, suggesting that when results from different cognitive domains such as executive functions and verbal fluency are analyzed together, bilingual effects amount to a zero-sum game. This finding was replicated by repeating the analysis, using the datasets of two recent meta-analyses. We propose that the equilibrium we observe between positive and negative outcomes may not be accidental. Contrary to widespread belief, advantageous and disadvantageous effects are not stand-alone outcomes in free variation. We reframe them as the connatural components of a dynamic trade-off, whereby enhanced performance in one cognitive measure is offset by an incurred cost in another domain.
26 agost, 2024
Autors:
Evelina Leivada, Fritz Günther & Vittoria Dentella
Títol:
Reply to Hu et al: Applying different evaluation standards to humans vs. Large Language Models overestimates AI performanceEditorial: PNAS 121(36), e2406752121 (National Academy of Sciences)
Data de publicació: 26 d'agost, 2024
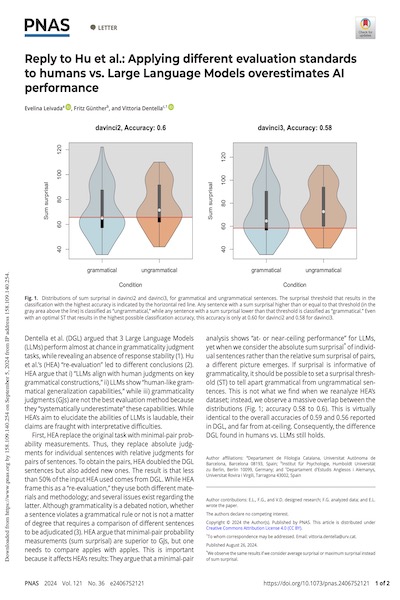
Text completDentella et al. (DGL) argued that 3 Large Language Models (LLMs) perform almost at chance in grammaticality judgment tasks, while revealing an absence of response stability (1). Hu et al.’s (HEA) “re-evaluation” led to different conclusions (2). HEA argue that i) “LLMs align with human judgments on key grammatical constructions,” ii) LLMs show “human-like grammatical generalization capabilities,” while iii) grammaticality judgments (GJs) are not the best evaluation method because they “systematically underestimate” these capabilities. While HEA’s aim to elucidate the abilities of LLMs is laudable, their claims are fraught with interpretative difficulties.
19 abril, 2024

Autors:
Evelina Leivada, Vittoria Dentella & Fritz Günther
Títol:
Biolinguistics, vol.18Editorial: PsychOpen
Data de publicació: 19 abril, 2024
Text completWe identify and analyze three caveats that may arise when analyzing the linguistic abilities of Large Language Models. The problem of unlicensed generalizations refers to the danger of interpreting performance in one task as predictive of the models’ overall capabilities, based on the assumption that because a specific task performance is indicative of certain underlying capabilities in humans, the same association holds for models. The human-like paradox refers to the problem of lacking human comparisons, while at the same time attributing human-like abilities to the models. Last, the problem of double standards refers to the use of tasks and methodologies that either cannot be applied to humans or they are evaluated differently in models vs. humans. While we recognize the impressive linguistic abilities of LLMs, we conclude that specific claims about the models’ human-likeness in the grammatical domain are premature.
3 abril, 2025

Autors:
Masullo, Casado, Leivada & Sorace
Títol:
Register variation and linguistic background modulate accuracy in detecting morphosyntactic errorsEditorial: Isogloss. Open Journal of Romance Linguistics
Data de publicació: 30-03-2025
Pàgines: 36 Més informació
Text completLinguistic register is defined as a variety of language shaped by different situational settings. Adapting to register is crucial for successful communication and involves the processing of language features related to register variation. Few studies have focused on the impact of linguistic register on language processing. Our research investigates whether register variation affects the detection of linguistic errors. To determine if linguistic background further impacts the way we deal with register, our sample includes monolingual, bilingual, and bidialectal participants. All groups completed an acceptability judgement task in Italian that features Subject-Verb agreement mismatches presented in high and low register. The results reveal a significant impact of linguistic register on accuracy: morphosyntactic errors are better detected in low-register stimuli. Furthermore, different trends characterize the tested groups. While monolinguals show more similar accuracy rates for low- and high-register sentences, the bilingual groups tend to better spot errors in low-register stimuli. Our findings suggest that register plays an important role in the processing of morphosyntactic errors, highlighting the need to consider both its cognitive and social dimensions. Moreover, the variation observed among the tested groups underscores that language processing can be influenced by factors related to the sociolinguistic dimensions of each linguistic community.



